
摘要:蛋白抗原表位预测算法及抗原多肽设计原则是构成南京德泰生物抗体定制服务的重要组成部分。
为了获取识别天然蛋白的抗体,有两种方式可以选择。一种是利用重组蛋白的方式获取尽可
能接近天然条件下的重组蛋白,然后刺激试验动物免疫系统,进而获取相应抗体。这种方式获取抗体的成功率较高且效价较好;另一种是预测天然蛋白的抗原决定簇,这种抗原决定簇最终体现为多肽形式,将其与相应的载体偶联后刺激试验动物免疫系统,也可以获取相应的抗体。这种方式的选择有其特殊需要。德泰生物提供这两种类型的抗体定制服务。
蛋白质表面部分可以使免疫系统产生抗体的区域叫抗原决定簇。一般抗原决定簇是由 5-8 氨基酸或碳水基团组成,它可以是由连续序列(蛋白质一级结构)组成或由不连续的蛋白质三维结构组成。
目前蛋白质抗原表位预测的方法大致可以分为两类,一类是基于蛋白质高级结构预测,像beta-转角、膜蛋白跨膜区预测等;一种是基于氨基酸的统计学倾向性,像亲水性(hydrophilicity)、弹性(flexibility)、表面可接触性(surface accessibility)、抗原倾向性(antigenic propensity)。具体算法请参考相关文献,部分文献如下:
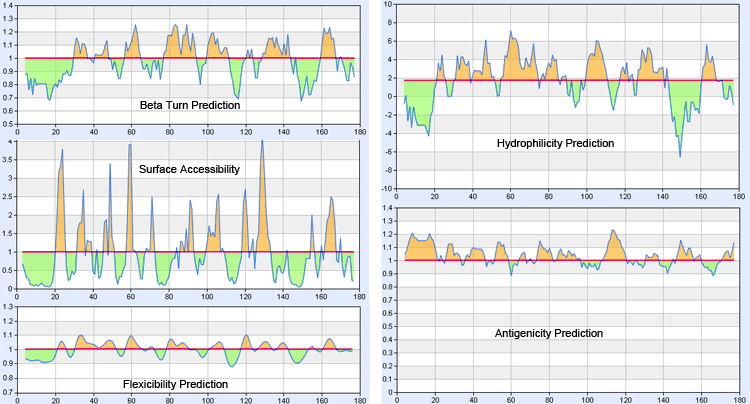
相关抗原表位预测工具: www.detaibio.com/tools/epitope-prediction.html
不同算法预测出的候选多肽序列有所不同,需要综合考虑各种预测方法,同时结合实际应用进行最终选择。
最终选择的多肽序列一般在15-20个碱基。单个抗原决定簇一般包含5-8个碱基,那么15-20个碱基的多肽一般会包含1个或更多个抗原决定簇。相对长一些的多肽段能够更好的保持和天然蛋白的一致性,更容易产生抗体。由于多肽是采用化学方法合成出来的,我们也要考虑到多肽合成的难度及其良好的可溶性。
我们一般会选择亲水区的多肽,其可溶性一般没太大问题,但是这些区域也会包含疏水性的碱基(如亮氨酸、色氨酸、异亮氨酸、缬氨酸、苯丙氨酸)。如果可能,尽量少选择带有这类氨基酸的多肽。谷氨酰胺由于容易和肽链形成氢键而导致多肽不可溶,所以具有多个谷氨酸的多肽也要尽量避免。
半胱氨酸有利于将多肽偶联到载体蛋白上。所以应该保留多肽N端或C端的半胱氨酸,以便于载体蛋白偶联,从而具有较好的免疫原性。同时两个或更多半胱氨酸的情况需要避免,因为它会造成多肽链之间形成二硫键,进而导致不溶和结构变化。当选择的多肽缺少半胱氨酸时,我们可以在N端或C端加上半胱氨酸。
脯氨酸采用顺式酰胺键的方式存在于多肽中,而一般多肽的酰胺键是反式的,它的存在更能使多肽与天然蛋白相似。在大多数情况下,脯氨酸的存在更能形成自然结构,增强多肽的免疫原性。
如果抗体用于识别目标蛋白翻译后的修饰区域(如磷酸化、糖基化位点),那么我们的多肽就需要在两端稍作延伸。从另一个方面来说,如果抗体用于识别翻译修饰前的蛋白,那么相应的位点需要去除掉。
跨膜区蛋白段需要移出掉,因为跨膜区无法被抗体接触到。
林林总总,经过层层规则的过滤,最终我们会保留至少3条多肽(经验证明3条多肽可以使抗体识别天然蛋白的成功率达到93%以上)。
化学合成的多肽,在抗体生产中,其浓度也影响着免疫应答反应。纯度越高,特异性免疫应答反应越强。
南京德泰生物生物信息工具提供的抗原决定簇预测软件能够综合多种预测算法,找到最符合要求的多肽,提高了预测成功率,减少多肽合成成本。






南京德泰生物工程有限公司 Nanjing Detai Bioengineering Co.,Ltd. ©2025 All Rights Reserved
 苏公网安备32011202001300
苏公网安备32011202001300