
蛋白表达专题:涵盖四大蛋白表达与纯化(原核(大肠杆菌),哺乳动物,酵母系统)介绍、原理、操作步骤及实验FAQ,内容全面、丰富。
蛋白表达通常是指生物体内蛋白质的合成、修饰以及调控过程。在表达系统的相关研究中,表达是指利用基因重组技术表达蛋白质的过程。本文主要关注后一个话题,着重阐述重组蛋白生产过程中的主要细胞机制(cellular machinery)。
蛋白在细胞内的合成和调控取决于功能的需求,蛋白质的遗传信息都储存在DNA的模板中,并由转录过程中产生的信使RNA(mRNA)进行解码,遗传信息通过一个mRNA编码,然后翻译为蛋白质。转录是指遗传信息从DNA传递到mRNA的过程,而翻译是指蛋白通过mRNA指定的序列进行合成的过程。
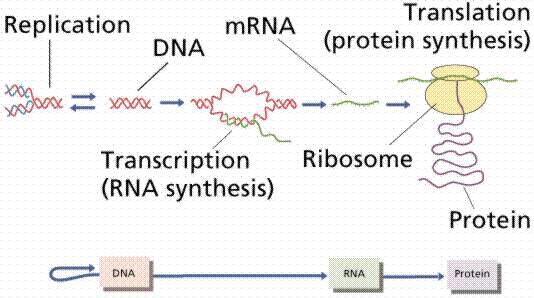
转录和翻译的简略示意图,描述了从DNA碱基对序列(基因)到形成氨基酸多肽序列(蛋白质)的过程。
在原核细胞中,转录和翻译是同时进行的。翻译甚至在成熟的mRNA转录产物完全合成前就已经开始了。这种转录翻译同时进行的方式被称为转录翻译的耦合(coupled)。而在真核细胞中,转录发生在细胞核内,翻译或蛋白合成的场所则是在细胞质中,俩者是分开且依次发生的。
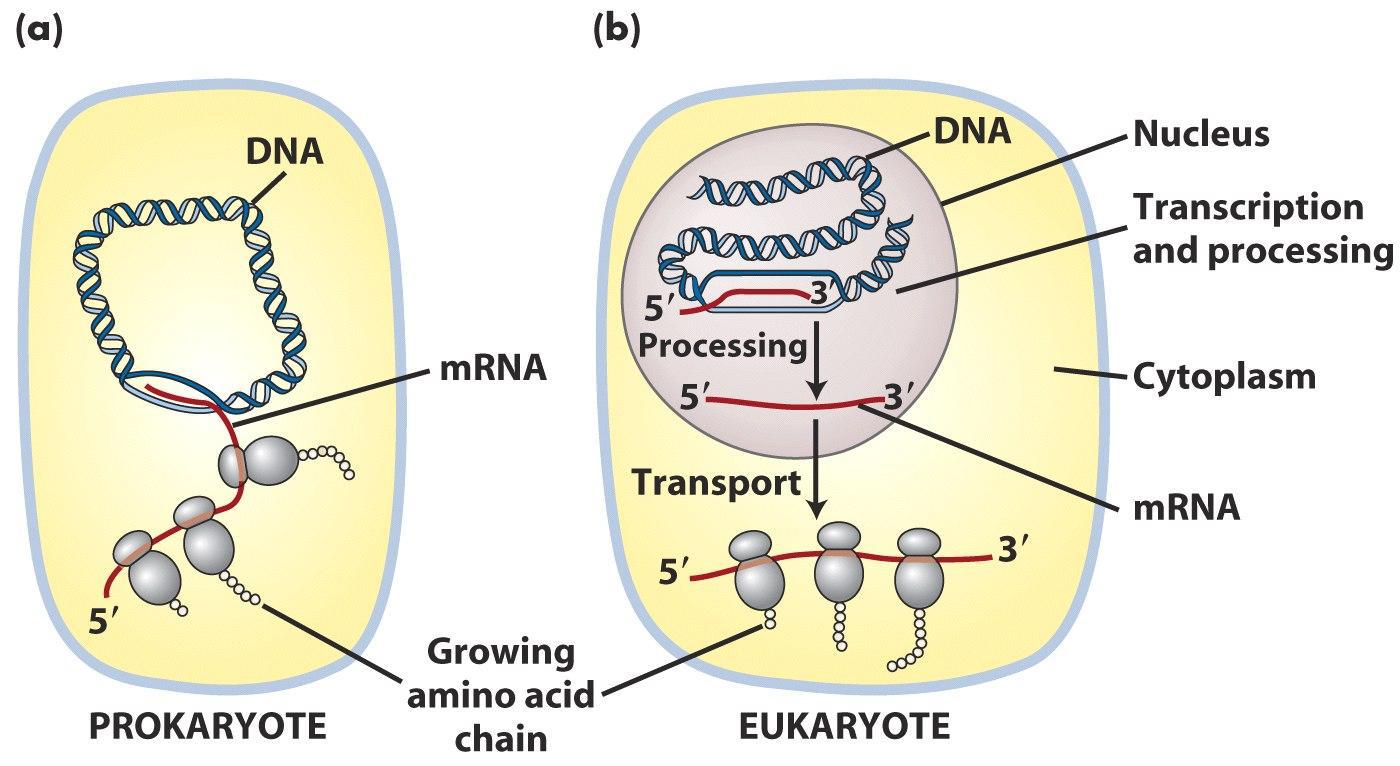
真核和原核的转录翻译对比图
原核生物和真核生物的转录的过程都包括三个步骤:起始,延伸和终止。当双链DNA解旋并与RNA聚合酶结合时转录开始。一旦转录开始,RNA聚合酶就会从DNA中释放出来。转录的过程的调控依赖激活蛋白和阻遏蛋白,同时也与真核的染色质结构有关。在原核生物中,mRNA的原始转录产物一般不需要加工修饰,翻译往往在转录完成前就开始了。然而真核细胞中,原始转录产物则需要进一步的加工——除去内含子,mRNA的5′端添加“帽子”,mRNA 3′末端在多聚腺苷酸聚合酶参与下加上了一段多个腺嘌呤序列(poly A尾)。修饰后的mRNA移动到细胞质中进行翻译。
翻译或蛋白的合成是一个复杂的过程,包括起始,延长和终止三个步骤。整个过程需要生物大分子的协同作用,如核糖体,转运RNA(tRNA),mRNA等;同时还需要很多的蛋白因子和小分子蛋白,如氨基酸,ATP,GTP以及其它辅助因子。这些特殊的翻译因子存在于翻译的每一步中(详情见下表)。原核和真核的翻译过程整体上是相似的,但在部分过程中依然存在着区别。
在起始阶段,核糖体的小亚基会引发t-RNA扫描mRNA,识别并结合mRNA5’端的起始密码子(AUG)。核糖体的大亚基和小亚基在起始密码子处链接并形成起始复合物。蛋白因子和mRNA参与到起始密码子的识别和起始复合物形成的过程中。延长阶段,tRNA会结合到特定的氨基酸上(这通常被称为tRNA的装载作用)并在核糖体中聚合形成肽,氨基酸通过转录产物的mRNA序列不断添加到正在增长的肽段中。最终,新生多肽在终止密码子处停止翻译。同时,核糖体释放mRNA,准备开始新一轮的翻译。
原核生物与真核生物翻译过程中的主要组成部分概述
| 组成 | 原核 | 真核 |
|---|---|---|
| 核糖体 | 30S和50S亚基 | 40S和60S亚基 |
| 模板或mRNA | 转录后,mRNA转录产物不需要进一步的修饰 mRNA是多顺反子并包含多个起始位点 |
转录后,mRNA除去非编码区(内含子),并且在mRNA的5’端和3’端分别加入“帽子”结构(M7甲基鸟嘌呤)和聚腺苷酸序列。 “帽子”结构和poly A尾在mRNA转移到细胞质的过程起到很重要的作用,可以保证翻译的正确性以及mRNA在其他功能中的稳定性。 mRNA通常是单顺反子。 |
| 翻译的特点 | Shine-Dalgarno序列存在于mRNA转录物中,是核糖体亚基中的一段互补序列。 SD序列有助于mRNA在起始位点与核糖体的结合准确。 新生多肽的第一位氨基酸是甲酰化的甲硫氨酸。 |
翻译的起始发生在俩个方面: Cap-dependent翻译:“帽结构”和帽结合蛋白负责核糖体结合mRNA并识别正确的密码子。mRNA的5’端第一个AUG密码子作为起始密码子,有时Kozak 序列会出现在起始密码子附近。 Cap-independent翻译:核糖体与mRNA是通过mRNA的“内部核糖体进入位点”(IRES)进行结合。 |
| 起始因子 | 三个已知启动因子:IF1,IF2,IF3 | 三个以上的经磷酸化调节的起始因子,在真核翻译中,启动步骤通常是限制步骤(rate-limiting step) |
| 延伸因子 | EF-Tu,EF-Ts,EF-G | EF1(α, β, γ)和EF2 |
| 终止或释放因子 | RF1和RF-2 | eRF-1 |
翻译后的多肽会采用多种加工方式来完成其蛋白结构或调节细胞活性。翻译后修饰(PTMs)是指各种添加或改变蛋白化学结构的方法,PTMs在整体细胞生物学中起到至关重要的作用。
翻译后修饰的类型包括:
在一般情况下,蛋白质组学研究涉及调查的一个蛋白的许多方面,如结构、功能、修饰、定位或蛋白质的相互作用等。为了研究特定蛋白的生物学调节作用,研究人员通常需要采用生产手段制造出感兴趣的功能蛋白。
对于已知大小和复杂性的蛋白,不能采用化学合成的方法。相反,活细胞及其细胞器通常被作为模板基因合成蛋白的场所。
不同的蛋白质,既可以使用简单的DNA综合构建,也可以利用已知的DNA序列在体外重组构建。因此,特殊基因的DNA模板无论带不带额外的亲和标签序列,均可以构造为表达模板。通过这样的重组DNA模板表达出来的蛋白被称为重组蛋白。
传统蛋白表达纯化方式包括重组载体转染细胞,细胞培养以及转录翻译目的蛋白。通常情况下,会先裂解细胞提取蛋白,并对提取的蛋白进行纯化。原核细胞和真核细胞的体内蛋白表达系统已被广泛应用,系统的选择取决于表达蛋白的种类,功能活性和预期收益等。
原核表达系统具有易于培养,增长快速和产量高等优点。然而,多域(multi-domain)真核蛋白在细菌内的表达往往是不成功的,因为细胞无法满足翻译后修饰或分子折叠的需求。同时,许多表达的蛋白很容易形成不溶性的包涵体——如果没有合适的变性剂和复杂的复性程序很难恢复蛋白的天然构型。
哺乳动物体内表达系统虽然会产生活性蛋白,但也有着产量低,生产成本高以及细胞培养时间长等缺点。此外,在体内的表达系统不利于高通量(high throughput protein)蛋白合成或对宿主细胞有毒性的蛋白表达。
无细胞蛋白表达是采用全细胞翻译兼容提取物(translation-compatible extracts of whole cells)在体外合成蛋白质。原则上,全细胞提取物中含有所有的用于转录,翻译及翻译后修饰的大分子组件。这些组件包括RNA聚合酶,调控因子,转录因子,核糖体和tRNA。
在添加辅助因子,核苷酸和特定的基因模板的情况下,几小时内就可以合成目的蛋白。
虽然这种表达方式无法应用到规模化生产中,但无细胞蛋白表达系统与传统的体内表达系统相比,仍具有很多优势:无细胞表达系统可以使重组蛋白快速合成,免除细胞培养的麻烦;无细胞系统可以使用修饰的氨基酸标签,以及表达会因蛋白酶而快速降解的蛋白。而且通过体外表达的方法,能够同时表达多种不同的蛋白。(例如,通过从许多不同的重组DNA模板中进行一个小规模表达来检测蛋白突变)
化学合成的蛋白被应用于标记非天然氨基酸(proteins labeled with unnatural amino acids),在特定位点标记蛋白或表达对生物系统有毒性的蛋白。化学合成法能够生产出高纯度的蛋白,但这种方法只适用于小分子蛋白质和多肽。化学合成法合成的蛋白产量非常低,且价格昂贵。
如果您在原核蛋白表达过程中遇到什么问题,请联系我们。






南京德泰生物工程有限公司 Nanjing Detai Bioengineering Co.,Ltd. ©2025 All Rights Reserved
 苏公网安备32011202001300
苏公网安备32011202001300